
Weighted Random Forests for Evaluating Financial Credit Risk
Keywords:
credit risk analysis, decision tree, imbalanced data, random forestAbstract
Credit evaluation of customers is a critical issue in financial organizations. Classification algorithms have been
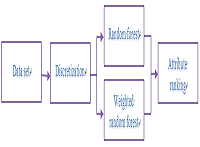
proposed for credit evaluation in recent years, and the class distribution in the financial data for those studies are not skewed. However, only a small proportion of customers will be the cases for bad credit. Financial records should be considered as an imbalanced data set for analyzing credit risk. Ensemble algorithms that make predictions by group decisions generally have relatively high accuracy than the ones inducing only one model from data. This study introduces a mechanism based on the weighted random forest to improve the prediction accuracy on the records with bad credit. This mechanism is tested on two financial data sets to demonstrate that it can achieve relatively high performance in evaluating credit risk and that the number of decision trees in a forest is not helpful. Critical attributes are also identified to provide practical meanings for credit risk analysis.
References
B. Baesens, T. Van Gestel, S. Viaene, M. Stepanova, J. Suykens, and J. Vanthienen, “Benchmarking state-of-the-art
classification algorithms for credit scoring,” Journal of the Operational Research Society, vol. 54, no. 6, pp. 627-635, June
C. L. Huang, M. C. Chen, and C. J. Wang, “Credit scoring with a data mining approach based on support vector machines,”
Expert Systems with Applications, vol. 33, no. 4, pp. 847-856, November 2007.
P. Danenas and G. Garsva, “Selection of support vector machines based classifiers for credit risk domain,” Expert Systems
with Applications, vol. 42, no. 6, pp. 3194-3204, April 2015.
N. Mohammadi and M. Zangeneh, “Customer credit risk assessment using artificial neural networks,” International
Journal of Information Technology and Computer Science, vol. 8, pp. 58-66, March 2016.
J. Yao and C. Lian, “A new ensemble model based support vector machine for credit assessing,” International Journal of
Grid and Distributed Computing, vol. 9, no. 6, pp. 159-168, 2016.
A. AghaeiRad, N. Chen, and B. Ribeiro, “Improve credit scoring using transfer of learned knowledge from self-organizing
map,” Neural Computing and Applications, vol. 28, no. 6, pp. 1329-1342, June 2017.
Q. Zhang, J. Wang, A. Lu, S. Wang, and J. Ma, “An improved SMO algorithm for financial credit risk assessment
evidence from China’s banking,” Neurocomputing, vol. 272, pp. 314-325, January 2018.
D. K. Gupta and S. Goyal, “Credit risk prediction using artificial neural network algorithm,” International Journal of
Modern Education and Computer Science, vol. 10, no. 5, pp. 9-16, May 2018.
S. Ben Jabeur, A. Sadaaoui, A. Sghaier, and R. Aloui, “Machine learning models and cost-sensitive decision trees for bond
rating prediction,” Journal of the Operational Research Society, DOI: 10.1080/01605682.2019.1581405, April 2019.
L. Munkhdalai, T. Munkhdalai, O. E. Namsrai, J. Y. Lee, and K. H. Ryu, “An empirical comparison of machine-learning
methods on bank client credit assessments,” Sustainability, vol. 11, pp. 1-23, January 2019.
M. Z. Abedin, C. Guotai, Fahmida-E-Moula, A. S. M. S. Azad, and M. S. U. Khan, “Topological applications of
multilayer perceptrons and support vector machines in financial decision support systems,” International Journal of
Finance and Economics, vol. 24, pp.474-507, January 2019.
D. Liang, C. F. Tsai, and H. T. Wu, “The effect of feature selection on financial distress prediction,” Knowledge-Based
Systems, vol. 73, pp. 289-297, January 2015.
S. Dahiya, S. S. Handa, and N. P. Singh, “A rank aggregation algorithm for ensemble of multiple feature selection
techniques in credit risk evaluation,” International Journal of Advanced Research in Artificial Intelligence,
vol. 5, pp. 1-8, October 2016.
F. N. Koutanaei, H. Sajedi, and M. Khanbabaei, “A hybrid data mining model of feature selection algorithms and
ensemble learning classifiers for credit scoring,” Journal of Retailing and Consumer Services, vol. 27, pp. 11-23,
November 2015.
L. Breiman, “Random forests,” Machine Learning, vol. 45, no. 1, pp. 5-32, October 2001.
N. Ghatasheh, “Business analytics using random forest trees for credit risk prediction: a comparison study,” International
Journal of Advanced Science and Technology, vol. 72, pp. 19-30, 2014.
M. Malekipirbazari and V. Aksakalli, “Risk assessment in social lending via random forests,” Expert Systems with
Applications, vol. 42, no. 10, pp. 4621-4631, June 2015.
V. Garcia, A. I. Marques, and J. S. Sanchez, “Exploring the synergetic effects of sample types on the performance of
ensembles for credit risk and corporate bankruptcy prediction,” Information Fusion, vol. 47, pp. 88-101, May 2019.
A. Coser, M. M. Maer-matei, and C. Albu, “Predictive models for loan default risk assessment,” Economic Computation
and Economic Cybernetics Studies and Research, vol. 53, pp. 149-165, June 2019.
M. Oskarsdottir, C. Bravo, C. Sarraute, J. Vanthienen, and B. Baesens, “The value of big data for credit scoring: enhancing
financial inclusion using mobile phone data and social network analytics,” Applied Soft Computing, vol. 74, pp. 26-39,
January 2019.
V. López, A. Fernández, S. García, V. Palade, and F. Herrera, “An insight into classification with imbalanced data:
empirical results and current trends on using data intrinsic characteristics,” Information Sciences, vol. 250, pp. 113-141,
November 2013.
G. E. Batista, R. C. Prati, and M. C. Monard “A study of the behavior of several methods for balancing machine learning
training data,” ACM SIGKDD Explorations, vol. 6, pp. 20-29, 2004.
A. Estabrooks, T. Jo, and N. Japkowicz, “A multiple resampling method for learning from imbalanced data sets,”
Computational Intelligence, vol. 20, pp. 18-36, 2004.
N. V. Chawla, K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer, “SMOTE: synthetic minority over-sampling technique,”
Journal of Artificial Intelligence Research, vol. 16, pp. 321-357, 2002.
M. A. Tahir, J. Kittler, K. Mikolajczyk, and F. Yan, “A multiple expert approach to the class imbalance problem using
inverse random under sampling,” Proceedings of the Eighth International Workshop on Multiple Classifier Systems,
pp. 82-91, 2009.
Y. Li, H. Guo, X. Liu , Y. Li, and J. Li, “Adapted ensemble classification algorithm based on multiple classifier system
and feature selection for classifying multi-class imbalanced data,” Knowledge-Based Systems, vol. 94, pp. 88-104,
February 2016.
Z. Sun, Q. Song, X. Zhu, H. Sun, B. Xu, and Y. Zhou, “A novel ensemble method for classifying imbalanced data,”
Pattern Recognition, vol. 48, no. 5, pp.1623-1637, May 2015.
R. Barandela, J. S. Sánchez, V. García, and E. Rangel, “Strategies for learning in class imbalance problems,” Pattern
Recognition, vol. 36, pp. 849-851, 2003.
B. Krawczyk, “Learning from imbalanced data: open challenges and future directions,” Progress in Artificial Intelligence,
vol. 5, pp. 221-232, 2016.
L. I. Kuncheva and J. J. Rodríguez, “A weighted voting framework for classifiers ensembles,” Knowledge and
Information Systems, vol. 38, no. 2, pp. 259-275, February 2014.
C. Chen, “Using random forest to learn imbalanced data,” Ph.D. Thesis, Department of Statistics, University of California,
Berkeley, July 2004.
U. M. Fayyad and K. B. Irani, “Multi-interval discretization of continuous valued attributes for classification learning,”
Proceedings of the Thirteenth International Joint Conference on Artificial Intelligence, 1993, pp. 1022-1027.
Published
How to Cite
Issue
Section
License
Submission of a manuscript implies: that the work described has not been published before that it is not under consideration for publication elsewhere; that if and when the manuscript is accepted for publication. Authors can retain copyright of their article with no restrictions. Also, author can post the final, peer-reviewed manuscript version (postprint) to any repository or website.

Since Oct. 01, 2015, PETI will publish new articles with Creative Commons Attribution Non-Commercial License, under The Creative Commons Attribution Non-Commercial 4.0 International (CC BY-NC 4.0) License.
The Creative Commons Attribution Non-Commercial (CC-BY-NC) License permits use, distribution and reproduction in any medium, provided the original work is properly cited and is not used for commercial purposes


