
Estimating Classification Accuracy for Unlabeled Datasets Based on Block Scaling
DOI:
https://doi.org/10.46604/ijeti.2023.11975Keywords:
prediction accuracy estimation, unlabeled dataset, machine learning, convolutional neural network, vocal detectionAbstract
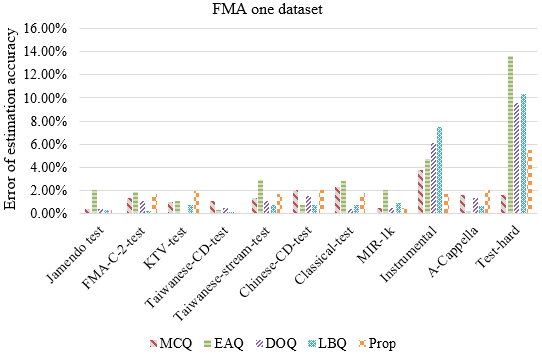
This paper proposes an approach called block scaling quality (BSQ) for estimating the prediction accuracy of a deep network model. The basic operation perturbs the input spectrogram by multiplying all values within a block by , where is equal to 0 in the experiments. The ratio of perturbed spectrograms that have different prediction labels than the original spectrogram to the total number of perturbed spectrograms indicates how much of the spectrogram is crucial for the prediction. Thus, this ratio is inversely correlated with the accuracy of the dataset. The BSQ approach demonstrates satisfactory estimation accuracy in experiments when compared with various other approaches. When using only the Jamendo and FMA datasets, the estimation accuracy experiences an average error of 4.9% and 1.8%, respectively. Moreover, the BSQ approach holds advantages over some of the comparison counterparts. Overall, it presents a promising approach for estimating the accuracy of a deep network model.
References
S. D. You, C. H. Liu, and W. K. Chen, “Comparative Study of Singing Voice Detection Based on Deep Neural Networks and Ensemble Learning,” Human-Centric Computing and Information Sciences, vol. 8, no. 1, article no. 34, December 2018.
S. D. You, C. H. Liu, and J. W. Lin, “Improvement of Vocal Detection Accuracy Using Convolutional Neural Networks,” KSII Transactions on Internet and Information Systems, vol. 15, no. 2, pp. 729-748, February 2021.
M. Ramona, G. Richard, and B. David, “Vocal Detection in Music with Support Vector Machines,” IEEE International Conference on Acoustics, Speech and Signal Processing, pp. 1885-1888, March-April 2008.
M. Defferrard, K. Benzi, P. Vandergheynst, and X. Bresson, “FMA: A Dataset for Music Analysis,” https://doi.org/10.48550/arXiv.1612.01840, September 2017.
X. Zhang, Y. Yu, Y. Gao, X. Chen, and W. Li, “Research on Singing Voice Detection Based on a Long-Term Recurrent Convolutional Network with Vocal Separation and Temporal Smoothing,” Electronics, vol. 9, no. 9, article no. 1458, September 2020.
D. Bhaskaruni, F. P. Moss, and C. Lan, “Estimating Prediction Qualities without Ground Truth: A Revisit of the Reverse Testing Framework,” 24th International Conference on Pattern Recognition, pp. 49-54, August 2018.
B. Lakshminarayanan, A. Pritzel, and C. Blundell, “Simple and Scalable Predictive Uncertainty Estimation Using Deep Ensembles,” Advances in Neural Information Processing Systems, vol. 30, pp. 6405-6416, December 2017.
Y. Gal and Z. Ghahramani, “Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning,” Proceedings of the 33rd International Conference on International Conference on Machine Learning, vol. 48, pp. 1050-1059, June 2016.
C. Blundell, J. Cornebise, K. Kavukcuoglu, and D. Wierstra, “Weight Uncertainty in Neural Network,” Proceedings of the 32nd International Conference on International Conference on Machine Learning, vol. 37, pp. 1613-1622, July 2015.
S. D. You, H. C. Liu, and C. H. Liu, “Predicting Classification Accuracy of Unlabeled Datasets Using Multiple Deep Neural Networks,” IEEE Access, vol. 10, pp. 44627-44637, 2022.
C. L. Hsu, D. Wang, J. S. R. Jang, and K. Hu, “A Tandem Algorithm for Singing Pitch Extraction and Voice Separation from Music Accompaniment,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 20, no. 5, pp. 1482-1491, July 2012.
B. Logan and S. Chu, “Music Summarization Using Key Phrases,” IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No.00CH37100), vol. 2, pp. II749- II752, June 2000.
J. Salamon, E. Gomez, D. P. W. Ellis, and G. Richard, “Melody Extraction from Polyphonic Music Signals: Approaches, Applications, and Challenges,” IEEE Signal Processing Magazine, vol. 31, no. 2, pp. 118-134, March 2014.
Y. E. Kim and B. Whitman, “Singer Identification in Popular Music Recordings Using Voice Coding Features,” Proceedings of the 3rd International Conference on Music Information Retrieval, article no. 17, October 2002.
Z. Ju, P. Lu, X. Tan, R. Wang, C. Zhang, S. Wu, et al., “TeleMelody: Lyric-to-Melody Generation with a Template-Based Two-Stage Method,” https://doi.org/10.48550/arXiv.2109.09617, November 2022.
W. Fan and I. Davidson, “Reverse Testing: An Efficient Framework to Select amongst Classifiers under Sample Selection Bias,” Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 147-156, August 2006.
Y. Ovadia, E. Fertig, J. Ren, Z. Nado, D. Sculley, S. Nowozin, et al., “Can You Trust Your Model’s Uncertainty? Evaluating Predictive Uncertainty Under Dataset Shift,” Advances in Neural Information Processing Systems, vol. 32, pp. 13991-14002, December 2019.
S. Mohsen, W. M. F. Abdel-Rehim, A. Emam, and H. M. Kasem, “A Convolutional Neural Network for Automatic Brain Tumor Detection”, Proceedings of Engineering and Technology Innovation, vol. 24, pp. 15-21, August 2023.
K. Y. Chen, C. Y. Chang, Z. R. Tsai, C. T. Lee, and Z. Y. Shae, “Tea Verification Using Triplet Loss Convolutional Network,” Advance in Technology Innovation, vol. 6, no. 4, pp. 199-212, October. 2021.
S. J. Sushma, S. C. Prasanna Kumar, and T. A. Assegie, “A Cost-Sensitive Logistic Regression Model for Breast Cancer Detection,” The Imaging Science Journal, vol. 70, no. 1, pp. 10-18, 2022.
S. D. You, H. C. Cho, and C. H. Liu, “Vocal Detection Using Convolution Neural Networks with Visualization Tools,” IEEE International Conference on Consumer Electronics-Asia, pp. 1-2, October 2022.
M. T. Ribeiro, S. Singh, and C. Guestrin “Why Should I Trust You?”: Explaining the Predictions of Any Classifier,” Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 1135-1144, August 2016.
T. A. Assegie, “Evaluation of Local Interpretable Model-Agnostic Explanation and Shapley Additive Explanation for Chronic Heart Disease Detection,” Proceedings of Engineering and Technology Innovation, vol. 23, pp. 48-59, January 2023.
K. Kumari and S. Yadav, “Linear Regression Analysis Study,” Journal of the Practice of Cardiovascular Sciences, vol. 4, no. 1, pp. 33-36, January-April 2018.
H. M. Huang, W. K. Chen, C. H. Liu, and S. D. You, “Singing Voice Detection Based on Convolutional Neural Networks,” 7th International Symposium on Next Generation Electronics, pp. 1-4, May 2018.
M. D. Zeiler, “ADADELTA: An Adaptive Learning Rate Method,” https://doi.org/10.48550/arXiv.1212.5701, December 2012.
S. C. Pravin, S. P. K. Sabapathy, S. Selvakumar, S. Jayaraman, and S. V. Subramani, “An Efficient DenseNet for Diabetic Retinopathy Screening,” International Journal of Engineering and Technology Innovation, vol. 13, no. 2, pp. 125-136, April 2023.
Published
How to Cite
Issue
Section
License
Copyright (c) 2023 Shingchern D. You, Kai-Rong Lin, Chien-Hung Liu

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.
Copyright Notice
Submission of a manuscript implies: that the work described has not been published before that it is not under consideration for publication elsewhere; that if and when the manuscript is accepted for publication. Authors can retain copyright in their articles with no restrictions. Also, author can post the final, peer-reviewed manuscript version (postprint) to any repository or website.

Since Jan. 01, 2019, IJETI will publish new articles with Creative Commons Attribution Non-Commercial License, under Creative Commons Attribution Non-Commercial 4.0 International (CC BY-NC 4.0) License.
The Creative Commons Attribution Non-Commercial (CC-BY-NC) License permits use, distribution and reproduction in any medium, provided the original work is properly cited and is not used for commercial purposes.






.jpg)


