
Comparative Analysis of Japanese Speech: Applying Dynamic Time Warping and Precise Word Segmentation for Pronunciation Assessment
DOI:
https://doi.org/10.46604/ijeti.2026.16049Keywords:
Japanese characters, speech analysis, pronunciation assessment, dynamic time warping, word segmentationAbstract
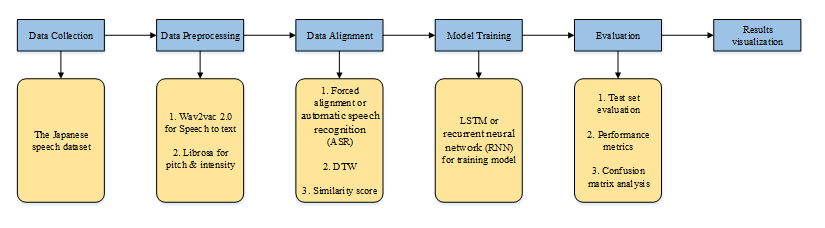
To address the limitations of conventional pronunciation assessment in handling acoustic variability. This research presents a novel framework for Japanese pronunciation assessment that integrates self-supervised speech representations with temporal alignment to facilitate granular feedback. The proposed methodology utilizes Wav2Vec 2.0 for automated, high-precision word segmentation, followed by dynamic time warping (DTW) to quantify similarity in pitch-accent patterns. Experimental results indicate that the long short-term memory (LSTM)-based classification model achieves an accuracy of 92.5% with an F1-score of 0.92, demonstrating high reliability in pronunciation discrimination. Furthermore, the system effectively isolates prosodic deviations through word-level distance heatmaps, providing actionable diagnostic feedback for learners. This study contributes a robust, model-driven pipeline that enhances the diagnostic capability of computer-assisted pronunciation training (CAPT) systems for Japanese language learning.
References
B. Jilson, "A Brief Exploration of the Development of the Japanese Writing System," Honors Thesis, University at Albany, State University of New York, USA, 2013.
U. Kiran, "MFCC Technique for Speech Recognition," https://www.analyticsvidhya.com/blog/2021/06/mfcc-technique-for-speech-recognition/, 2021.
Z. K. Abdul and A. K. Al-Talabani, "Mel Frequency Cepstral Coefficient and Its Applications: A Review," IEEE Access, vol. 10, pp. 122136-122158, 2022.
G. Kaur, M. Srivastava, and A. Kumar, "Analysis of Feature Extraction Methods for Speaker Dependent Speech Recognition," International Journal of Engineering and Technology Innovation, vol. 7, no. 2, pp. 78-88, 2017.
Y. Permanasari, E. H. Harahap, and E. P. Ali, "Speech Recognition Using Dynamic Time Warping (DTW)," Proceedings of Journal of Physics: Conference Series, vol. 1366, no. 1, article no. 012091, 2019.
S. Jiang and Z. Chen, "Application of Dynamic Time Warping Optimization Algorithm in Speech Recognition of Machine Translation," Heliyon, vol. 9, no. 11, article no. e21625, 2023.
K. Sheoran, A. Bajgoti, R. Gupta, N. Jatana, G. Dhand, C. Gupta, et al., "Pronunciation Scoring With Goodness of Pronunciation and Dynamic Time Warping," IEEE Access, vol. 11, pp. 15485-15495, 2023.
S. Takamichi, R. Sonobe, K. Mitsui, Y. Saito, T. Koriyama, N. Tanji, et al., "JSUT and JVS: Free Japanese Voice Corpora for Accelerating Speech Synthesis Research," Acoustical Science and Technology, vol. 41, no. 5, pp. 761-768, 2020.
A. V. Oppenheim, R. W. Schafer, J. R. Buck, Discrete-Time Signal Processing, 2nd ed. Upper Saddle River, NJ, USA: Prentice Hall, 1999.
J. B. Allen and L. R. Rabiner, "A Unified Approach to Short-Time Fourier Analysis and Synthesis," Proceedings of the IEEE, vol. 65, no. 11, pp. 1558-1564, 1977.
B. Boashash, Ed., Time-Frequency Signal Analysis and Processing: A Comprehensive Reference. Oxford, UK: Longman Scientific & Technical, 2003.
S. Schneider, A. Baevski, R. Collobert, and M. Auli, "wav2vec: Unsupervised Pre-Training for Speech Recognition," Proceedings of Interspeech 2019, Graz, Austria, pp. 3465-3469, 2019.
A. Baevski, H. Zheng, M. Auli, and A. Mohamed, "wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations," Proceedings of the 34th International Conference on Neural Information Processing Systems, vol. 33, pp. 12449-12460, 2020.
H. Sakoe and S. Chiba, "Dynamic Programming Algorithm Optimization for Spoken Word Recognition," IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 26, no. 1, pp. 43-49, 1978.
M. Müller, "Dynamic Time Warping," Information Retrieval for Music and Motion. Berlin, Heidelberg: Springer, pp. 69-84, 2007.
D. Berndt and J. Clifford, "Using Dynamic Time Warping to Find Patterns in Time Series," Proceedings of the 3rd International Conference on Knowledge Discovery and Data Mining, AAAI Workshop, pp. 359-370, 1994.
P. M. Rogerson-Revell, "Computer-Assisted Pronunciation Training (CAPT): Current Issues and Future Directions," RELC Journal, vol. 52, no. 1, pp. 189-205, 2021.
E. Kim, J. Jeon, H. Seo, and H. Kim, "Automatic Pronunciation Assessment Using Self-Supervised Speech Representation Learning," Proceedings of Interspeech 2022, Incheon, Korea, pp. 1411-1415, 2022.
S. M. Witt and S. J. Young, "Phone-Level Pronunciation Scoring and Assessment for Interactive Language Learning," Speech Communication, vol. 30, no. 2-3, pp. 95-108, 2000.
L. Chen, J. Tao, S. Ghaffarzadegan, and Y. Qian, "End-to-End Neural Network Based Automated Speech Scoring," Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, pp. 6872-6876, 2018.
Published
How to Cite
Issue
Section
License
Copyright (c) 2026 Supaporn Bundasak, Kollathee Wisawayotanan, Chen Chien-Chang

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.
Copyright Notice
Submission of a manuscript implies: that the work described has not been published before that it is not under consideration for publication elsewhere; that if and when the manuscript is accepted for publication. Authors can retain copyright in their articles with no restrictions. Also, author can post the final, peer-reviewed manuscript version (postprint) to any repository or website.

Since Jan. 01, 2019, IJETI will publish new articles with Creative Commons Attribution Non-Commercial License, under Creative Commons Attribution Non-Commercial 4.0 International (CC BY-NC 4.0) License.
The Creative Commons Attribution Non-Commercial (CC-BY-NC) License permits use, distribution and reproduction in any medium, provided the original work is properly cited and is not used for commercial purposes.






.jpg)


