
Multi-Dimensional Framework for Reliable and Instructionally Aligned Question–Answer Generation with Large Language Models
DOI:
https://doi.org/10.46604/ijeti.2026.16326Keywords:
QA generation, instructionally aligned prompting, semantic chunking, FAISS retrieval, hallucination reductionAbstract
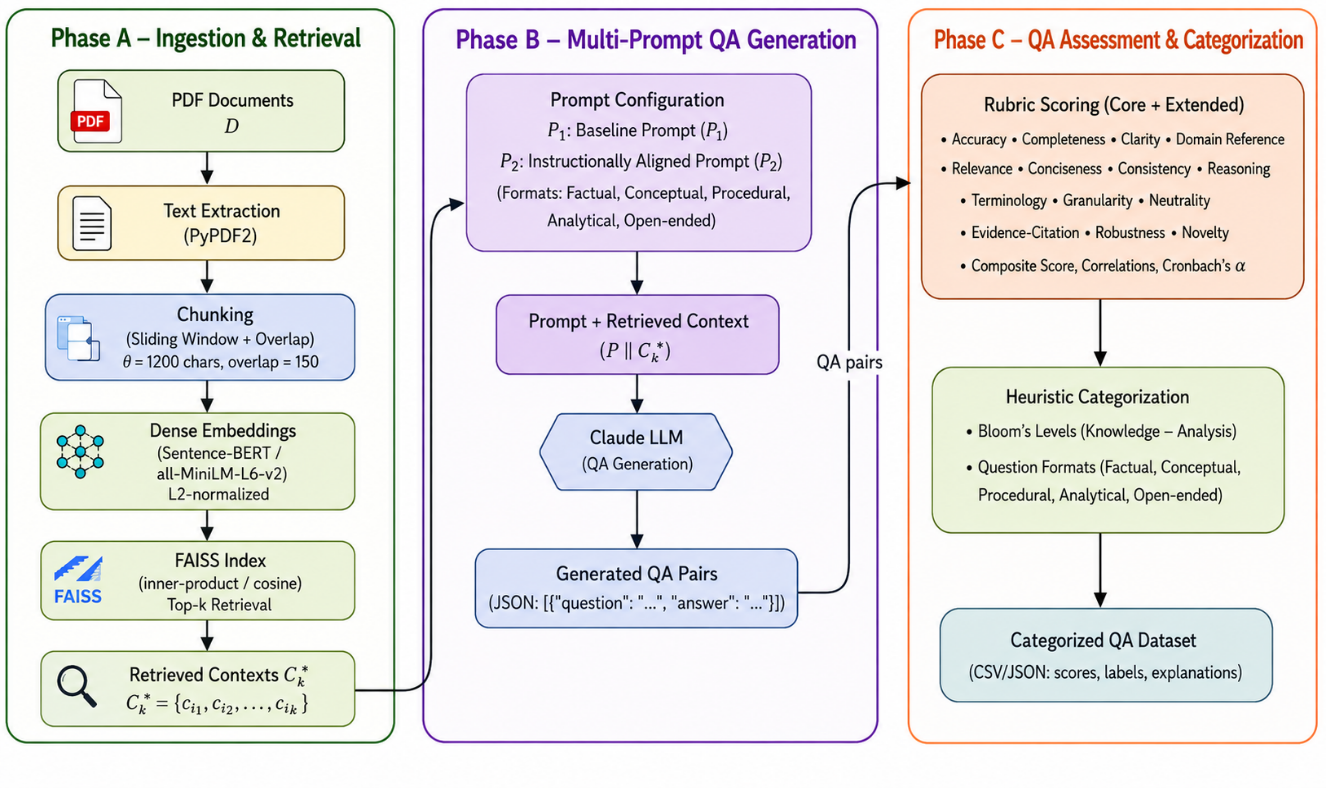
This study presents a multi-dimensional framework for reliable, instructionally aligned question–answer (QA) generation from academic portable document formats (PDFs) using an evidence-grounded claude configuration. The pipeline integrates semantic document chunking, facebook ai similarity search (FAISS)-based dense retrieval, guided by a standard QA prompt and an instructionally aligned prompt guided by Bloom’s cognitive levels to generate factual, conceptual, procedural, analytical, and open-ended questions. A rubric-based evaluation framework assesses factual grounding, reasoning quality, and instructional relevance. Results show that the evidence-grounded, instructionally aligned setting improves factual grounding and increases overall rubric scores. It also reduces hallucinations, and enhances higher-order cognitive coverage and question-format diversity. The framework is presented as a lightweight proof of concept using claude-3-Haiku, while broader cross-model validation and alternative retrieval strategies remain important directions for future work. These findings demonstrate the educational utility and interpretability of evidence-grounded QA generation.
References
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, et al., “Language Models Are Few-Shot Learners,” Proceedings of the 34th International Conference on Neural Information Processing Systems, vol. 33, article no. 159, pp. 1877-1901, 2020.
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, et al., “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer,” Journal of Machine Learning Research, vol. 21, no. 140, pp. 5485-5551, 2020.
A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, and N. Fiedel, “PaLM: Scaling Language Modeling with Pathways,” Journal of Machine Learning Research, vol. 24, no. 1, article no. 240, pp. 1-113, 2023.
L. Caruccio, S. Cirillo, G. Polese, G. Solimando, S. Sundaramurthy, and G. Tortora, “Claude 2.0 Large Language Model: Tackling a Real-World Classification Problem with a New Iterative Prompt Engineering Approach,” Intelligent Systems with Applications, vol. 21, article no. 200336, 2024.
H. Alhawasi and A. Youssef, “Using LLMs for Evaluating QA Systems: Exploration and Assessment,” Proceedings of the 2024 2nd International Conference on Foundation and Large Language Models (FLLM), IEEE, pp. 462-469, 2024.
A. Surabhi and S. Martha, “Precision in Conciseness: Exploring Large Language Models for Enhanced Document Summarization,” AIP Conference Proceedings, vol. 3298, no. 1, article no. 020003, 2025.
A. Karaca and B. Kılcan, “The Adventure of Artificial Intelligence Technology in Education: Comprehensive Scientific Mapping Analysis,” Participatory Educational Research, vol. 10, no. 4, pp. 144-165, 2023.
Y. Tian, A. Liu, Y. Dai, K. Nagato, and M. Nakao, “Systematic Synthesis of Design Prompts for Large Language Models in Conceptual Design,” CIRP Annals, vol. 73, no. 1, pp. 85-88, 2024.
Z. Liu, P. Agrawal, S. Singhal, V. Madaan, M. Kumar, and P. K. Verma, “LPITutor: An LLM Based Personalized Intelligent Tutoring System Using RAG and Prompt Engineering,” PeerJ Computer Science, vol. 11, article no. e2991, 2025.
S. Farquhar, J. Kossen, L. Kuhn, and Y. Gal, “Detecting Hallucinations in Large Language Models Using Semantic Entropy,” Nature, vol. 630, pp. 625-630, 2024.
M. Chelli, J. Descamps, V. Lavoué, C. Trojani, M. Azar, M. Deckert, et al., “Hallucination Rates and Reference Accuracy of ChatGPT and Bard for Systematic Reviews: Comparative Analysis,” Journal of Medical Internet Research, vol. 26, no. 1, article no. e53164, 2024.
M. Khamassi, M. Nahon, and R. Chatila, “Strong and Weak Alignment of Large Language Models with Human Values,” Scientific Reports, vol. 14, no. 1, article no. 19399, 2024.
S. AI Faraby, A. Romadhony and Adiwijaya, “Analysis of LLMs for Educational Question Classification and Generation,” Computers and Education: Artificial Intelligence, vol. 7, article no. 100298, 2024.
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” Proceedings of the 34th International Conference on Neural Information Processing Systems, article no. 793, pp. 9459-9474, 2020.
J. Song, X. Wang, J. Zhu, Y. Wu, X. Cheng, R. Zhong, et al., “RAG-HAT: A Hallucination-Aware Tuning Pipeline for LLM in Retrieval-Augmented Generation,” Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pp. 1548-1558, 2024.
E. Kamalloo, S. Upadhyay, and J. Lin, “Towards Robust QA Evaluation via Open LLMs,” Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 2811-2816, 2024.
J. Ling and M. Afzaal, “Automatic Question-Answer Pairs Generation Using Pre-Trained Large Language Models in Higher Education,” Computers and Education: Artificial Intelligence, vol. 6, article no. 100252, 2024.
E. Page, G. Meyers, and E. K. Billings, “Theory to Practice: A Framework for Generative AI,” Intersection: A Journal at the Intersection of Assessment and Learning, vol. 5, no. 4, pp. 114-126, 2024.
S. R. Addula, M. K. Meesala, P. Ravipati, and G. S. Sajja, “A Hybrid Autoencoder and Gated Recurrent Unit Model Optimized by Honey Badger Algorithm for Enhanced Cyber Threat Detection in IoT Networks,” Security and Privacy, vol. 8, no. 6, article no. e70086, 2025.
G. Izacard and E. Grave, “Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering,” Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pp. 874-880, 2021.
J. Lee, W. Yoon, S. Kim, D. Kim, S. Kim, C. H. So, et al., “BioBERT: A Pre-Trained Biomedical Language Representation Model for Biomedical Text Mining,” Bioinformatics, vol. 36, no. 4, pp. 1234-1240, 2020.
C. Wang, S. Cheng, Q. Guo, Y. Yue, B. Ding, Z. Xu, et al., “Evaluating Open-QA Evaluation,” Proceedings of the 37th International Conference on Neural Information Processing Systems, article no.3367, pp. 77013-77042, 2023.
E. Usta, “Lifelong Learning Motivation Scale (LLMs): Validity and Reliability Study,” Journal of Teacher Education and Lifelong Learning, vol. 5, no. 1, pp. 429-438, 2023.
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks,” Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 3982-3992, 2019.
A. Pathak, R. Gandhi, V. Uttam, A. Ramamoorthy, P. Ghosh, A. R. Jindal, et al., “Rubric Is All You Need: Improving LLM-Based Code Evaluation with Question-Specific Rubrics,” Proceedings of the 2025 ACM Conference on International Computing Education Research V.1, pp. 181-195, 2025.
D. Di Nuzzo, E. Vakaj, H. Saadany, E. Grishti, and N. Mihindukulasooriya, “Automated Generation of Competency Questions Using Large Language Models and Knowledge Graphs,” Proceedings of the 3rd NLP4KGC@SEMANTICs, 2024.
E. H. S. Y. Elim, “Promoting Cognitive Skills in AI-Supported Learning Environments: The Integration of Bloom’s Taxonomy,” Education 3–13, vol. 54, no. 3, pp. 1-11, 2024.
A. Surabhi and S. Martha, EDURAG-QA: A Retrieval-Augmented, Bloom-Classified Framework for Educational Question–Answer Generation, Indian Patent, 202641027220 A, 2026.
Published
How to Cite
Issue
Section
License
Copyright (c) 2026 Anuradha Surabhi, Sheshikala Martha

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.
Copyright Notice
Submission of a manuscript implies: that the work described has not been published before that it is not under consideration for publication elsewhere; that if and when the manuscript is accepted for publication. Authors can retain copyright in their articles with no restrictions. Also, author can post the final, peer-reviewed manuscript version (postprint) to any repository or website.

Since Jan. 01, 2019, IJETI will publish new articles with Creative Commons Attribution Non-Commercial License, under Creative Commons Attribution Non-Commercial 4.0 International (CC BY-NC 4.0) License.
The Creative Commons Attribution Non-Commercial (CC-BY-NC) License permits use, distribution and reproduction in any medium, provided the original work is properly cited and is not used for commercial purposes.






.jpg)


